Usando o Python com o Oracle Database 11g
Postado em Dezembro 2014
Finalidade Neste tutorial, mostramos como usar o Python com o Oracle Database 11g.
Para ter acesso a outros manuais, leia os seguintes artigos de Oracle by Examples: Desenvolvendo uma aplicação Web do Python com o Oracle Database 11g (em inglês) Usando o Python com o Oracle Database 11g (em inglês)
DuraçãoAproximadamente 1 hora
Resenha Python é uma linguagem de programação dinâmico de uso geral muito popular. Ante o crescente uso de ambientes de desenvolvimento ou frameworks, o Python também está ganhando muitos adeptos no campo das aplicações Web. Se você quer usar o Python em combinação com um banco de dados Oracle, este tutorial vai ajudá-lo, através de exemplos, a dar os primeiros passos. Se você estiver usando o Python pela primeira vez, consulte o Anexo: Conceitos básicos do Python para compreender a linguagem.
Requisitos Para esta sessão prática, você já tem instalado:
- Oracle Database 11gR2, com o usuário "pythonhol" e a senha "welcome" (diferencia maiúsculas de minúsculas). As tabelas de exemplo deste esquema foram tomadas do esquema de Recursos Humanos. "HR", do Oracle.
- Python 2.4 com a extensão cx_Oracle 5.0.2.
- Ambiente de desenvolvimento Django 1.1.
- Os arquivos que serão usados ao longo deste tutorial estão no diretório /home/pythonhol em que você fez o login.
Conexão com o Oracle Para criar uma conexão com o Oracle, siga os passos detalhados na sequência:
Revise o seguinte código, localizado no arquivo connect.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
print con.version
con.close()
O módulo cx_Oracle é importado a fim de fornecer a interface API necessária para acessar o banco de dados Oracle. Assim, é possível incluir numerosos módulos integrados ou de terceiros nas sequências do Python.
O método connect() recebe o usuário "pythonhol", a senha "welcome" e a cadeia de conexão. Neste caso, é usada a sintaxe da cadeia de conexão Easy Connect do Oracle. Ela contém o endereço IP da máquina do usuário e o nome de serviço do banco de dados "orcl".
O método close() fecha a conexão. As conexões que não forem explicitamente fechadas serão anuladas ao finalizar a sequência de comandos.
Em um terminal de linha de comando, execute:
python connect.py

Se a conexão for bem-sucedida, será mostrado o número de versão. Caso a conexão falhar, será lançada uma exceção.
No Python são usados recuos para indicar a estrutura do código. Diferentemente de muitas outras linguagens, no Python não há terminadores de linha, nem palavras-chave de início e final ou chaves para indicar blocos de código.
Abra connect.py em um editor. Insira dois espaços antes do comando print e salve o arquivo.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
print con.version
con.close()
Execute a sequência a seguir:
python connect.py

Não importa quantos espaços ou tabulações houver diante dos comandos desde que seu uso seja coerente em cada bloco. Neste caso, o interpretador do Python não espera um novo nível de blocos de código depois da chamada connect(), por isso adverte os diferentes recuos.
Em outros casos, como com "if" e blocos de laços (mostrado abaixo), é necessário conferir que todos os comandos de cada bloco tenham o mesmo recuo.
Se você estiver copiando e colando seções deste tutorial, verifique que os recuos do código colado sejam corretos antes de executar cada exemplo.
O Python trata tudo como um objeto. O objeto "con" tem um atributo "version", que é uma cadeia.
Modifique o código para usar também um método de cadeia "split":
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
ver = con.version.split(".")print ver
con.close()
Execute novamente o código no terminal de linha de comandos:
python connect.py

Obtém-se uma matriz como saída, que no Python é chamada "List" [lista].
As listas de Python podem ser acessadas mediante índices.
Modifique connect.py da seguinte maneira:
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
ver = con.version.split(".")
print verprint ver[0]print ver[-1]print ver[1:4]
con.close()
Execute novamente o código no terminal de linha de comandos:
python connect.py
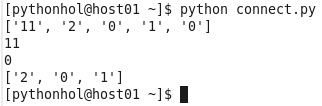
As listas do Python são de base zero, portanto, ver[0] mostra o primeiro elemento da lista. O último elemento da lista é ver[-1]. Com ver[1:4] é gerado um intervalo da lista. O comando retorna os elementos encontrados da posição 1 até a posição 4, sem incluí-la.
No Python há métodos associados às listas, e estas também podem ser manipuladas mediante operadores.
Modifique connect.py da seguinte maneira:
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
ver = con.version.split(".")
print ver
print ver.index("1")
ver.remove("2")
print verver1 = ["11", "g"]
ver2 = ["R", "2"]
print ver1 + ver2
con.close()
python connect.py
Execute novamente o código no terminal de linha de comandos:
python connect.py
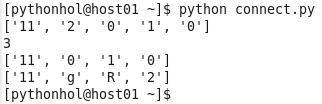
O método index("1") retorna o índice do elemento "1", contando do zero. O método remove("2) elimina um elemento da lista. O operador "+" pode ser usado para unir duas listas.
Outros tipos de dados do Python são o "Dictionary" [dicionário], uma matriz associativa, e o "Tuple" [tupla]; este último é similar à lista, porém, não pode ser modificado.
Laços podem ser usados para iterar através de listas.
Modifique connect.py da seguinte maneira:
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
ver = con.version.split(".")
for v in ver:
print v
if v == "11":
print "It's 11"
else:
print "Not 11"
con.close()
Certifique-se de deixar a quantidade adequada de espaços.
Os ":" são usados para indicar um bloco de código. Os primeiros comandos print e if têm o mesmo recuo porque ambos estão dentro do laço.
Execute novamente o código no terminal de linha de comandos:
python connect.py

O laço mostra e testa cada valor da lista, um de cada vez.
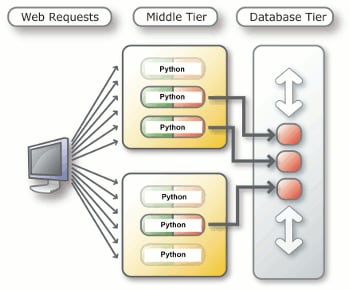
Usando o pool de conexões existentes de bancos de dados O pool de conexões existentes de bancos de dados (DRCP) é uma nova característica do Oracle Database 11g. Ele é útil para sequências de comandos de curta duração, como as usadas comumente pelas aplicações Web. Permite aumentar a quantidade de conexões à medida que o uso do web site aumenta. Permite que diversos processos do Apache em diferentes máquinas compartilhem um pequeno pool de processos do servidor de banco de dados. Sem a função DRCP, uma conexão do Python deve iniciar e fechar um processo do servidor.
Abaixo à esquerda, mostramos o diagrama de um cenário sem pool. Cada sequência tem seu próprio processo no servidor de banco de dados. As sequências que não recorrem ao banco de dados ainda mantêm a conexão até esta ser anulada e o servidor fechar. Abaixo à direita, mostramos um diagrama de conexão com DRCP. As sequências podem usar servidores de banco de dados de um pool de servidores e retorná-los quando não são mais necessários.

As sequências por lotes que realizar tarefas de execução prolongada em geral deveriam usar conexões não agrupadas. Neste tutorial, mostramos como usar conexões DRCP para aplicações novas ou existentes sem escrever nem alterar qualquer lógica das aplicações. Siga os passos elencados a seguir:
Revise o seguinte código, contido no arquivo connect_drcp.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol', 'welcome', '127.0.0.1:/orcl:pooled',
cclass = "HOL", purity = cx_Oracle.ATTR_PURITY_SELF)
print con.version
con.close()
É semelhante a connect.py, mas acrescentando "pooled" à cadeia da conexão. Além disso, uma classe de conexão "HOL" é passada para o método connect() e a "pureza" do método é definida como a constante ATTR_PURITY_SELF.
A classe de conexão indica ao pool de servidores de banco de dados que as conexões estão relacionadas. A informação da sessão (como o formato default de data) poderia se conservar entre chamadas de conexão, representando benefícios em relação ao desempenho. A informação da sessão será descartada se um pool de servidores for depois reutilizado por uma aplicação com outro nome de classe de conexão.
As aplicações que não deveriam compartilhar informação das sessões em nenhum caso deveriam usar classes de conexão diferentes e/ou utilizar ATTR_PURITY_NEW para forçar a criação de uma nova sessão. O procedimento anterior diminui a escalabilidade geral, mas também evita o uso inadequado de informações de sessões nas aplicações.
Execute connect_drcp.py
python connect_drcp.py

Novamente, a saída é só a versão do banco de dados. Não é necessário modificar a lógica da sequência para aproveitar as vantagens do pool de conexões DRCP.
Criando uma pesquisa simples Uma tarefa comum no desenvolvimento de aplicações Web é a pesquisa em um banco de dados e a amostragem dos resultados em um navegador Web. Diferentes funções podem ser usadas para pesquisar um banco de dados Oracle, mas os elementos básicos das pesquisas são sempre os mesmos: 1. Analisar o comando para sua execução. 2. Unir valores de dados (opcional). 3. Executar o comando. 4. Obter os resultados do banco de dados. Para criar uma pesquisa simples e mostrar os resultados, siga os passos detalhados na sequência.
Revise o seguinte código, contido no arquivo query.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
cur.execute('select * from departments order by department_id')
for result in cur:
print result
cur.close()
con.close()
O método cursor() abre um cursor que é usado nos comandos.
O método execute() analisa e executa o comando.
O laço obtém cada linha a partir do cursor e mostra.
Execute a sequência em uma janela do terminal:
python query.py

Os resultados da pesquisa são mostrados como tuplas do Python, matrizes que não podem ser modificadas.
Pesquisando dados Há diferentes maneiras de pesquisar dados e um banco de dados Oracle. Siga os passos elencados a seguir:
Revise o seguinte código, contido no arquivo query_one.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.01/orcl')
cur = con.cursor()
cur.execute('select * from departments order by department_id')
row = cur.fetchone()
print row
row = cur.fetchone()
print row
cur.close()
con.close()
Nesta sequência é usado o método fetchone() para devolver só uma linha como uma tupla. Quando chamado várias vezes, retorna linhas consecutivas:
Execute a sequência em uma janela do terminal:
python query_one.py

Os dois chamados a fetchone() mostram dois registros.
Revise o seguinte código, contido no arquivo query_many.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
cur.execute('select * from departments order by department_id')
res = cur.fetchmany(numRows=3)print res
cur.close()
con.close()
O método fetchmany() retorna uma lista de tuplas. O parâmetro numRows indica que o método deveria retornar três linhas.
Execute a sequência em uma janela do terminal:
python query_many.py

O método retorna as primeiras três linhas da tabela como uma lista de tuplas. Revise o seguinte código, contido no arquivo query_all.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
cur.execute('select * from departments order by department_id')
res = cur.fetchall()print res
cur.close()
con.close()
Execute a sequência em uma janela do terminal:
python query_all.py

Nesta sequência é utilizado o método fetchall() para retornar todas as linhas. A saída é uma lista (denominação usada no Python para designar matrizes) de tuplas. Cada tupla contém os dados de uma linha.
A lista pode ser manipulada de qualquer forma admitida pelo Python. Edite query_all.py e modifique o código segundo indicado a seguir (em negrito); execute novamente.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
cur.execute('select * from departments order by department_id')
res = cur.fetchall()for r in res:
print r
cur.close()
con.close()

Agora, cada tupla é mostrada separadamente. A escolha do método de pesquisa de dados, fetch, vai depender de como você deseja processar os dados retornados.
Como melhorar o desempenho das pesquisas Nesta seção, mostramos como melhorar o desempenho das pesquisas aumentando a quantidade de linhas retornadas em cada lote do Oracle para o programa no Python. Siga os passos elencados a seguir:
Em primeiro lugar, crie uma tabela com muitas linhas. Revise a sequência
query_arraysize.sql a seguir.
set echo on
drop table bigtab;
create table bigtab (mycol varchar2(20));
begin
for i in 1..20000
loop
insert into bigtab (mycol) values (dbms_random.string('A',20));
end loop;
end;
/
show errors
commit;
Em uma janela do terminal, use SQL*Plus para executar a sequência:
sqlplus pythonhol/welcome@127.0.0.1/orcl
@query_arraysizeexit

Revise o código, contido no arquivo query_arraysize.py do diretório $HOME.
import time
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
start = time.time()
cur = con.cursor()
cur.arraysize = 100
cur.execute('select * from bigtab')
res = cur.fetchall()
# print res
# uncomment to display the query results
elapsed = (time.time() - start) print elapsed, " seconds"
cur.close()
con.close() Nesta sequência, é usado o módulo "time" [tempo] para medir o tempo da pesquisa. Arraysize [tamanho de matriz] é estabelecido em 100. Desta forma são gerados lotes de 100 registros de cada vez que serão retornados do banco de dados para uma memória cache no Python. Assim, a quantidade de "idas e voltas" do banco de dados é reduzida, reduzindo ao mesmo tempo a carga das redes e a quantidade de mudanças de contexto no servidor de bancos de dados. Os métodos fetchone(), fetchmany() e também fetchall() vão ler a memória cache antes de pedir novos dados ao banco de dados.
Execute a sequência a seguir em uma janela do terminal:
python query_arraysize.py

Atualize algumas vezes para ver os tempos médios.
Edite query_arraysize.py e substitua
cur.arraysize = 100
por
cur.arraysize = 2000
Execute a sequência mais algumas vezes e compare o desempenho usando um e outro valor de arraysize. Em geral, com matrizes de maior tamanho, o desempenho aumenta. Dependendo da velocidade de seu sistema, é possível que você tenha que usar para arraysize valores diferentes destes exemplos, a fim de perceber uma verdadeira diferença.
python query_arraysize.py

O valor default de arraysize no cx_Oracle é 50. O aumento de arraysize significa uma perda em termos de espaço. O aumento do valor de arraysize vai requerer mais memória no Python para armazenar temporariamente os registros.
Usando variáveis de ligação As variáveis de ligação [bind] permitem tornar a executar comandos com novos valores, sem ter que analisar novamente esses comandos. As variáveis de ligação aumentam a capacidade de reutilização do código e podem reduzir o risco de ataques de injeção de SQL. Para usar variáveis de ligação neste exemplo, realize os passos a seguir: . . .
Revise o seguinte código, contido no arquivo bind_query.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
cur.prepare('select * from departments where department_id = :id')
cur.execute(None, {'id': 210})
res = cur.fetchall()
print res cur.execute(None, {'id': 110})
res = cur.fetchall()
print res
cur.close()
con.close()
O comando inclui uma variáveis de ligação ":id". A declaração só é preparada uma vez, mas é executada duas vezes com valores diferentes para a cláusula WHERE.
O símbolo especial "None" é usado em vez do argumento de texto do comando para execute() pois o método prepare() já preparou o comando. O segundo argumento para a chamada ao método execute() é um dicionário do Python. Na primeira chamada a execute, esta matriz associativa tem o valor 210 para a chave de "id".
O primeiro execute usa o valor 210 para a pesquisa. O segundo execute usa o valor 110.
Execute a sequência a seguir em uma janela do terminal:
python bind_query.py

Na saída, são mostrados os dados dos dois departamentos.
O controlador cx.Oracle suporta ligações de matrizes para os comandos INSERT, melhorando em muito o desempenho em relação à inserção de linhas individuais.
Revise os seguintes comandos para criar uma tabela em que serão inseridos dados:
sqlplus pythonhol/welcome@127.0.0.1/orcl
drop table mytab;
create table mytab (id number, data varchar2(20));
exit
Execute SQL*Plus e copie e cole os comandos.

Revise o seguinte código, contido no arquivo bind_insert.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
rows = [ (1, "First" ),
(2, "Second" ),
(3, "Third" ),
(4, "Fourth" ),
(5, "Fifth" ),
(6, "Sixth" ),
(7, "Seventh" ) ]
cur = con.cursor()
cur.bindarraysize = 7
cur.setinputsizes(int, 20)
cur.executemany("insert into mytab(id, data) values (:1, :2)", rows)
#con.commit()
# Now query the results back
cur2 = con.cursor()
cur2.execute('select * from mytab')
res = cur2.fetchall()
print res
cur.close()cur2.close()con.close()
A matriz "rows" contém os dados a serem inseridos.
O tamanho da ligação de matrizes, bindarraysize, foi estabelecido em 7; isto é, as sete linhas serão inseridas em um único passo. A chamada setinputsizes() descreve as colunas. A primeira coluna é de tipo janeiro. A segunda coluna tem, no máximo, 20 bytes.
A chamada a executemany() insere as sete linhas.
A chamada a commit é comentada e não é executada.
A parte final da sequência pesquisa os resultados e mostra como uma lista de tuplas.
Execute a sequência a seguir em uma janela do terminal: python bind_insert.py

Os novos resultados são automaticamente revertidos no final da sequência; por isso, quando for novamente executada, sempre será mostrada a mesma quantidade de linhas na tabela.
Criando transações Quando manipulamos dados em um banco de dados Oracle (inserção, modificação ou remoção), antes de sua confirmação, os dados modificados ou novos estarão disponíveis apenas na sessão própria de trabalho com o banco de dados. Já confirmados no banco de dados, os dados modificados estarão disponíveis para outros usuários e sessões. Isso é chamado de transação do banco de dados. Siga os passos elencados a seguir:
Edite a sequência usada na seção anterior bind_insert.py e remova a marca de comentário da chamada a commit (///em negrito, a seguir):
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
rows = [ (1, "First" ),
(2, "Second" ),
(3, "Third" ),
(4, "Fourth" ),
(5, "Fifth" ),
(6, "Sixth" ),
(7, "Seventh" ) ]
cur = con.cursor()
cur.bindarraysize = 7
cur.setinputsizes(int, 20)
cur.executemany("insert into mytab(id, data) values (:1, :2)", rows)
con.commit()
# Now query the results back
cur2 = con.cursor()
cur2.execute('select * from mytab')
res = cur2.fetchall()
print res
cur.close()cur2.close()con.close()
O método commit() está na conexão, não no cursor. Execute novamente a sequência várias vezes e poderá ver que a quantidade de linhas da tabela aumenta a cada execução:
python bind_insert.py

Se você precisa aplicar uma reversão a uma sequência, pode usar o método con.rollback().
O normal é querer confirmar todos os dados ou nenhum. Fazer o seu próprio controle das transações costuma ter vantagens de desempenho e integridade dos dados.
Usando funções e procedimentos armazenados de PL/SQL PL/SQL é a extensão da linguagem procedimental do Oracle para SQL. Os procedimentos e as funções de PL/SQL são armazenados e executados no banco de dados. Usar PL/SQL permite a reutilização da lógica nas aplicações que trabalham com bancos de dados, independente do modo em que a aplicação acessar o banco de dados. Muitas operações envolvendo dados podem ser realizadas em PL/SQL em menos tempo que se os dados fossem extraídos e passados para um programa (por exemplo do Python) para seu processamento. O Oracle também é compatível com os procedimentos do Java armazenados. Neste tutorial, você vai criar em PL/SQL uma função e um procedimento armazenados para depois chamá-los em sequências do Python. Siga os passos elencados a seguir: . . . . .
Inicie SQL*Plus e crie uma nova tabela, ptab, com o seguinte comando:
sqlplus pythonhol/welcome@127.0.0.1/orcl
create table ptab (mydata varchar(20), myid number);
exit

Revise a sequência create_func.sql , a qual cria em PL/SQL a função myfunc() armazenada para inserir uma linha na tabela e retornar o dobro do valor inserido:
set echo on
create or replace function
myfunc(d_p in varchar2, i_p in number) return number as
begin
insert into ptab (mydata, myid) values (d_p, i_p);
return (i_p * 2);
end;
/
show errors
Inicie SQL*Plus e execute a sequência:
sqlplus pythonhol/welcome@127.0.0.1/orcl @create_func exit

Revise o seguinte código, contido no arquivo plsql_func.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
res = cur.callfunc('myfunc', cx_Oracle.NUMBER, ('abc', 2))
print res cur.close()
con.close()
Aqui é usado callfunc() para executar a função. A constante cx_oracle.NUMBER indica que o valor retornado pela função é numérico. Os dois parâmetros da função de PL/SQL são passados como tupla e enlaçados aos argumentos do parâmetro da função.
Execute a sequência a seguir em uma janela do terminal:
' python plsql_func.py
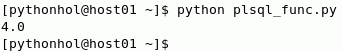
A saída é o resultado do cálculo realizado pela função de PL/SQL.
Para chamar um procedimento de PL/SQL, use o método cur.callproc().
Revise a sequência create_proc.sql , criada pelo procedimento myproc() de PL/SQL para aceitar dois parâmetros. O segundo parâmetro tem OUT como valor de retorno.
set echo on
create or replace procedure
myproc(v1_p in number, v2_p out number) as
begin
v2_p := v1_p * 2;
end;
/
show errors
Inicie SQL*Plus e execute a sequência:
sqlplus pythonhol/welcome@127.0.0.1/orcl @create_proc exit

Revise o seguinte código, contido no arquivo plsql_proc.py do diretório $HOME.
import cx_Oracle
con = cx_Oracle.connect('pythonhol/welcome@127.0.0.1/orcl')
cur = con.cursor()
myvar = cur.var(cx_Oracle.NUMBER)
cur.callproc('myproc', (123, myvar))
print myvar.getvalue()
cur.close()
con.close()
Nele, é criada a variável numérica myvar que vai conter o parâmetro OUT. O número 123 e o nome da variável de retorno são enlaçados aos parâmetros da chamada ao procedimento mediante uma tupla.
Execute a sequência a seguir em uma janela do terminal:
python plsql_proc.py

O método getvalue() mostra o valor retornado.
Notificações de pesquisa contínua As notificações de pesquisa contínua (também chamadas de notificações de mudanças no banco de dados, DCN) permitem que as aplicações recebam notificações se uma tabela é modificada, por exemplo, quando uma linha é inserida. Receber essas notificações pode ser útil em múltiplas circunstâncias, incluindo a invalidação da memória cache de nível intermediário. A memória cache pode conter alguns valores dependentes dos dados de uma tabela. Se a tabela for modificada, os dados armazenados na memória cache devem ser atualizados para incorporar a informação nova. Neste exemplo, mostramos o trabalho com eventos DCN no Python. Siga os passos elencados abaixo: . . . . . . .
Revise o seguinte código, contido no arquivo dcn.py do diretório $HOME.
import cx_Oracle
def DCNCallback(message):
print "Notification:"
for tab in message.tables:
print "Table:", tab.name
for row in tab.rows:
if row.operation & cx_Oracle.OPCODE_INSERT:
print "INSERT of rowid:", row.rowid
if row.operation & cx_Oracle.OPCODE_DELETE:
print "DELETE of rowid:", row.rowid con = cx_Oracle.Connection("pythonhol/welcome@127.0.0.1/orcl",
events = True)
subscriptionInsDel = con.subscribe(callback = DCNCallback,
operations = cx_Oracle.OPCODE_INSERT | cx_Oracle.OPCODE_DELETE,
rowids = True)
subscriptionInsDel.registerquery('select * from mytab')
raw_input("Hit Enter to conclude this demo\n")
A sequência cria uma função chamada DCNCallback(). A função será chamada quando uma tabela for modificada. O parâmetro "message" é um objeto cx_Oracle que conterá informação sobre as mudanças. A função só mostra os tipos de mudanças produzidas e a identificação das linhas afetadas. O corpo principal da sequencia está abaixo da função; observe que o nível de recuo de "con = ..." é igual ao de "def...". O corpo cria a conexão com o banco de dados, definindo o parâmetro "events = True" para permitir que o banco de dados envie uma notificação de evento ao Python quando houver uma mudança em uma tabela. A chamada a subscribe() registra a função DCNCallback() para ela ser invocada em um novo subprocesso quando um comando INSERT ou UPDATE for executado. Só pode ser executado um subprocesso do Python de cada vez. Python passa de um subprocesso para outro dependendo das necessidades. O parâmetro rowids = True permite acessar as identificações das linhas no retorno da chamada. A chamada a registerquery() registra uma pesquisa que seleciona o conteúdo completo da tabela MYTAB. Quando houver mudanças na tabela como resultado dos comandos UPDATE ou DELETE, o processo vai chamar a função DCNCallback(). A tabela MYTAB foi criada em uma seção anterior do tutorial. A sequência de código finaliza com uma chamada a raw_input() que espera a entrada de dados pelo usuário antes de encerrar o processo. Para executar o exemplo relacionado ao trabalho com DCN, abra duas janelas do terminal. Em uma, execute o seguinte:
python dcn.py

Este comando mostrará uma mensagem e esperará sem retornar o símbolo do sistema ou prompt. Deixe que o processo seja executado por um momento e continue com o próximo passo.
Na outra janela do terminal, escreva os seguintes comandos:
sqlplus pythonhol/welcome@127.0.0.1/orcl insert into mytab (id) values (11); commit;

Quando o comando commit for executado, a sequência do Python (volte para a primeira janela do terminal) receberá uma notificação e mostrará a mensagem de notificação de mudanças:

A identificação de linha será diferente em seu sistema.
Volte para a janela do terminal de SQL*Plus e remova a nova fila, executando os seguintes comandos de SQL:
delete from mytab where id = 11; commit;

A nova notificação será mostrada e, na janela de terminal do Python, poderá ler:

Experimente com diversas operações. Tente executar um comando INSERT seguido de DELETE antes da confirmação. Assim, vemos que, com cada operação, se recebe uma notificação.
Quando tiver finalizado, pressione Entrar [Enter] para concluir a demonstração na janela do Python e sair da sequência de código.

Modifique dcn.py para também enviar notificações quando houver atualizações, UPDATE, em MYTAB.
Na chamada a subscribe(), modifique o parâmetro de operations da seguinte forma:
operations = cx_Oracle.OPCODE_INSERT | cx_Oracle.OPCODE_DELETE | cx_Oracle.OPCODE_UPDATE,
Adicione um novo teste "if" na função DCNCallback:
if row.operation & cx_Oracle.OPCODE_UPDATE:
print "UPDATE of rowid:", row.rowid
Agora, a sequência de código dcn.py deveria ser assim (mudanças em negrito):
import cx_Oracle
def DCNCallback(message):
print "Notification:"
for tab in message.tables:
print "Table:", tab.name
for row in tab.rows:
if row.operation & cx_Oracle.OPCODE_INSERT:
print "INSERT of rowid:", row.rowid
if row.operation & cx_Oracle.OPCODE_DELETE:
print "DELETE of rowid:", row.rowid
if row.operation & cx_Oracle.OPCODE_UPDATE:
print "UPDATE of rowid:", row.rowid
con = cx_Oracle.Connection("pythonhol/welcome@127.0.0.1/orcl",
events = True)
subscriptionInsDel = con.subscribe(callback = DCNCallback,
operations = cx_Oracle.OPCODE_INSERT | cx_Oracle.OPCODE_DELETE
| cx_Oracle.OPCODE_UPDATE ,
rowids = True)
subscriptionInsDel.registerquery('select * from mytab')
raw_input("Hit Enter to conclude this demo\n")
No terminal do Python, reinicie a sequência:
No terminal de SQL*Plus, crie uma nova linha e atualize:
insert into mytab (id) values (11); update mytab set id = 12 where id = 11; commit;

A nova mensagem será mostrada.

Quando tiver finalizado, pressione Entrar para concluir a demonstração na janela do Python e sair da sequência de código.

As notificações de mudanças no banco de dados são uma forma eficiente de monitorar as alterações introduzidas nas tabelas. Também podem ser usadas quando qualquer linha de um subconjunto de linhas selecionado em uma consulta determinada for modificada.
Usando o ambiente de desenvolvimento Django O ambiente de desenvolvimento ou framework Django é um dos vários ambientes do Python, muito usados para a criação de aplicações Web. Neste exercício, criaremos uma aplicação Web simples com o Django. Primeiramente, mostra-se uma lista simples.
Para começar, crie um projeto no Django. Execute a sequência a seguir em uma janela do terminal:
django-admin.py startproject myproj

Para criar uma aplicação neste novo projeto, execute:
cd myproj
python manage.py startapp myappls -lls -l myapp

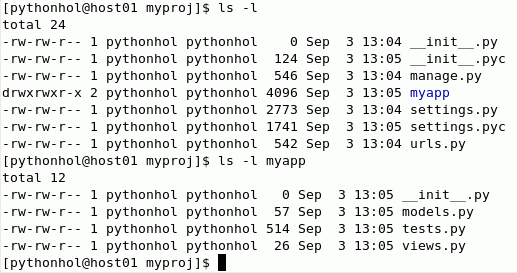
Agora, o diretório myproj inclui uma aplicação esqueleto: __init__.py: transforma o diretório em um pacote de Python; __init__.pyc: versão compilada do anterior; manage.py: sequência de código para administrar a aplicação; myapp: diretório para os arquivos da nova aplicação; settings.py: configurações do projeto; settings.pyc: versão compilada do anterior; urls.py: permite chamar métodos do Python em endereços URL.
O diretório myapp inclui: __init__.py: transforma o diretório em um pacote do Python; models.py: aplicação de classes do Python a cada tabela; tests.py: usado para construir um conjunto de teste; views.py: código do Python para gerar uma saída Web.
Para possibilitar a conexão da aplicação com o banco de dados, edite myproj/settings.py. Quase no topo do arquivo, modifique os parâmetros de conexão com o banco de dados para ficarem assim:
DATABASE_ENGINE = '
oracle'
DATABASE_NAME = '
127.0.0.1/orcl '
DATABASE_USER = '
pythonhol '
DATABASE_PASSWORD = '
welcome
'
Os valores de DATABASE_HOST e DATABASE_PORT podem ficar em branco.

No final do arquivo, adicione uma linha em INSTALLED_APPS para associar a aplicação ao projeto:
INSTALLED_APPS = (
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.sites',
'myproj.myapp'
)

Salve o arquivo e feche o editor.
Execute a aplicação esqueleto. Em uma janela do terminal, execute o seguinte comando dentro do diretório myproj:
python manage.py runserver
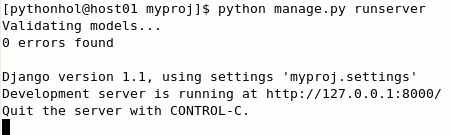
O comando inicia um servidor Web de desenvolvimento integrado na porta 8000 e espera as solicitações Web. O símbolo do sistema da shell não é retornado. Por enquanto, deixe o processo funcionando.
Abra o navegador Web e escreva a seguinte URL:
//127.0.0.1:8000/

Será mostrado o site predeterminado da aplicação do Django. Neste momento, a conexão com o banco de dados ainda não foi estabelecida.
Para construir a aplicação, primeiro terá que editar myproj/myapp/models.py e adicionar uma nova classe. Edite o arquivo e adicione o seguinte código no final:
class locations(models.Model):
location_id = models.IntegerField(primary_key = True)
street_address = models.CharField(max_length = 40)
postal_code = models.CharField(max_length = 12)
city = models.CharField(max_length = 30)
state_province = models.CharField(max_length = 25)
country_id = models.CharField(max_length = 2)
class Meta:
db_table = "locations"

Assim, uma alocação relacional de objetos é criada para a tabela LOCATIONS [localizações]. Cada atributo da classe corresponde a uma coluna já existente na tabela. A definição de primary_key = True indica que a coluna location_id é a chave primária do modelo. Especifica-se a longitude dos campos alfabéticos.
Em myproj/myapp/views.py deverá adicionar uma nova função para consultar o modelo e gerar a lista de saída. Adicione o seguinte código no final do arquivo:
from django.template import Context, loader
from django.http import HttpResponse
from myproj.myapp.models import locations
def index(request):
location_list = locations.objects.all().order_by('location_id')
tmpl = loader.get_template("index.html")
cont = Context({'locations': location_list})
return HttpResponse(tmpl.render(cont))
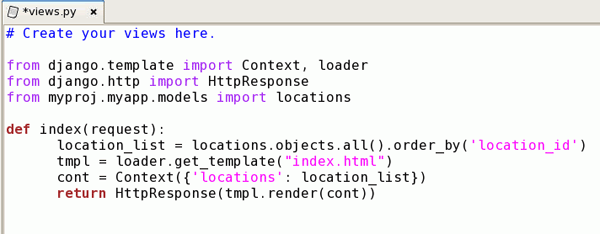
Com esses comandos é importado o modelo "locations" de models.py.
É criado um conjunto de consultas ordenado por LOCATION_ID. Este é usado para apresentar o arquivo do template index.html. A página HTML resultante é novamente enviada a Django para mostrar ao usuário.
É necessário criar o arquivo do template index.html para mostrar o conjunto de consultas quando "index" apresenta o modelo. Digite os seguintes comandos para criar o diretório de templates.
cd myproj/myapp mkdir templates cd templates Crie o arquivo myproj/myapp/templates/index.html com um editor. A seguir, incluímos o conteúdo do arquivo:
<html>
<head>
<title>Office Locations</title>
</head>
<body bgcolor="#ffffff">
<h1>Office Locations</h1>
<table border="1">
<tr>
<th>Location ID</th>
<th>Street Address</th>
<th>City</th>
</tr>
{% for loc in locations %}
<tr>
<td>{{loc.location_id}}</td>
<td>{{loc.street_address}}</td>
<td>{{loc.city}}</td>
</tr>
{% endfor %}
</table>
</body>
</html> 
No código acima é usada a sintaxe dos templates do Django, indicada mediante os pares de símbolos "{%" e "%}", de uma parte, e "{{" y "}}", da outra. A variável locations é o valor estabelecido pela ///chamada a Context na view. O laço cria uma linha na tabela HTML para cada linha do conjunto de consultas. Django pré-processa o arquivo index.html e cria o código HTML final que será enviado ao navegador Web.
Por último, é necessário dizer ao Django como chamar a nova função de view de índice. Edite myproj/urls.py e adicione no final a linha de url():
url(r'^myapp/', include('myproj.myapp.urls')),
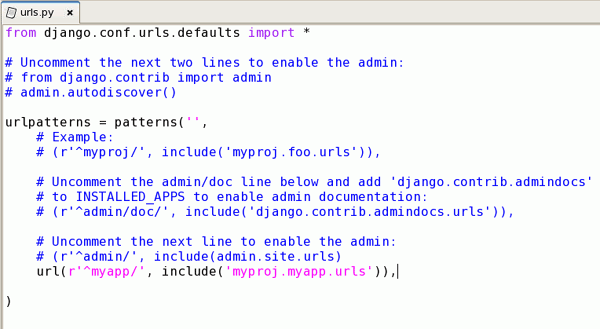
A cadeia r'^myapp/' é uma expressão regular. Sua inclusão permite que sejam enviadas as URLs incluindo "myapp/" ao arquivo myproj/mypass/urls.py para seu posterior processamento. A expressão regular diz que "myapp/" deve ir depois do nome do host da URL, da seguinte maneira:
//.../myapp/
Crie um novo arquivo myproj/myapp/urls.py para despachar as URLs da aplicação. Adicione o seguinte código:
from django.conf.urls.defaults import *
from myapp.views import index
urlpatterns = patterns('',
url(r'^$', index),
) 
Nele, é chamada a função "index" de views.py. Observe que a expressão regular agora não contém "myapp", pois esse valor já foi combinado no nível do projeto e não é enviado para o arquivo de alocação.
Na janela do terminal, use ^C para deter o servidor Web e reinicie da seguinte maneira:
python manage.py runserver
++++image django14-gif== where's django13-gif?==

No navegador Web, digite a URL da aplicação:
//127.0.0.1:8000/myapp/
O site da aplicação mostrará os três campos indicados da tabela LOCATIONS:

A visão geral da aplicação é: 1. A solicitação de //.../myapp no navegador Web chama o servidor Web de Django.
2. O despachante de URLs do Django executa todos os padrões URL do arquivo myproj/urls.py e escolhe o primeiro que coincidir com a URL. Este, por sua vez, chama o despachante de myproj/myapp/urls.py. O despachante chama a view "index", que é uma função de devolução de chamada do Python.
3. A view usa o modelo de dados para obter dados do banco de dados. Depois, o template "index.html" é apresentado com os dados da tabela LOCATIONS.
4. A view "index" retorna um objeto HttpResponse carregado com o template apresentado.
5. O Django apresenta o objeto HttpResponse no navegador Web.
A view usada neste exemplo foi feita para pesquisar dados. Também podem ser usadas visões para criar objetos salvos no banco de dados. A seguir, incluímos uma sequência de código que poderia ser usada com o modelo "locations" para inserir um novo objeto ou final em uma view:
new_loc = locations(
location_id = 7000,
street_address = "123 ABC",
postal_code = "9999",
city = "My City",
state_province = "My State",
country_id = "US")
new_loc.save()
Os seguintes comandos são usados para remover objetos:
loc = locations.objects.get(location_id__exact=1000) loc.delete()
Estas sequências também mostram a sintaxe usada para gerar uma pesquisa que retorna um registro único.
Usando AJAX e Python Nesta seção, mostramos como usar as técnicas do AJAX para modificar parte de uma página HTML sem voltar a carregar a página completa. No exemplo, a view "index" é modificada de modo que, quando um registro é clicado, o endereço completo da localização seja mostrado. Siga os passos elencados a seguir:
Nesta primeira parte, será criada uma nova view que retornará um endereço completo (incluindo o país) para uma localização determinada. Primeiramente, vamos estabelecer o modelo subjacente. Edite myproj/myapp/models.py: Antes do modelo "locations" existente, adicione um modelo para a tabela COUNTRIES [países]:
class countries(models.Model):
country_id = models.CharField(max_length = 2, primary_key = True)
country_name = models.CharField(max_length = 40)
region_id = models.IntegerField()
class Meta:
db_table = "countries"
Para explicitar a relação com a tabela LOCATIONS, modifique o modelo "locations" substituindo
country_id = models.CharField(max_length = 2)
por:
country = models.ForeignKey(countries)
Observe que "country_id" não vai se manter. Django adiciona automaticamente o sufixo "_id" para uma chave estrangeira e usa COUNTRY_ID nas tabelas COUNTRIES e LOCATIONS como coluna de união.

A seguir, mostramos o arquivo models.py completo (mudanças em negrito):
from django.db import models
# Create your models here.
class countries(models.Model):
country_id = models.CharField(max_length = 2, primary_key = True)
country_name = models.CharField(max_length = 40)
region_id = models.IntegerField()
class Meta:
db_table = "countries"
class locations(models.Model):
location_id = models.IntegerField(primary_key = True)
street_address = models.CharField(max_length = 40)
postal_code = models.CharField(max_length = 12)
city = models.CharField(max_length = 30)
state_province = models.CharField(max_length = 25)
country = models.ForeignKey(countries)
' class Meta:
db_table = "locations"
Edite myproj/myapp/views.py e adicione um novo método de view "address" para construir um endereço. Segue o arquivo completo:
# Create your views here.
from django.template import Context,
loader from django.http import HttpResponse
from myproj.myapp.models import locations
def index(request):
location_list = locations.objects.all().order_by('location_id')
tmpl = loader.get_template("index.html")
cont = Context({'locations': location_list})
return HttpResponse(tmpl.render(cont))
def address(request, lid):
address_list = locations.objects.select_related().filter(location_id=lid)
s = ""
for loc in address_list:
s = '[{"STREET_ADDRESS":"' + loc.street_address + \
'","CITY":"' + loc.city + \
'","POSTAL_CODE":"' + loc.postal_code + \
'","COUNTRY":"' + loc.country.country_name + '"}]'
return HttpResponse(s) Nota: Certifique-se de que o recuo seja idêntico ao mostrado acima e na captura de tela a seguir.

Para a view "address", será enviado o valor de parâmetro "lid" da URL que chama a view, como mostrado a seguir.
Com o método "select_related()", o Django realiza uma união interna entre as tabelas LOCATIONS e COUNTRIES, e lança todos os resultados correspondentes ao identificador de localização selecionado no objeto address_list associado ao conjunto de pesquisas. Django também enlaça o valor de "lid" por motivos de eficiência e segurança.
O laço "for" é uma forma simples de acessar o primeiro elemento resultante do conjunto de pesquisas. Como LOCATION_ID é uma chave primária, o laço só será executado uma vez.
A variável "s" é criada mediante a concatenação de cadeias para a linha adotar o formato JSON. JSON é um formato de texto comumente usado como protocolo leve para transferir dados entre Javascript no navegador Web e sequências de código do lado do servidor. Versões mais recentes do Python incluem métodos para codificação e decodificação de JSON que poderiam ser usadas em vez da concatenação de cadeias explícita mostrada acima.
Diferentemente da view "index" existente, neste caso, não é usado um template HTML. Só é usado HttpResponse() para mostrar a cadeia JSON no navegador Web.
Para que seja possível chamar a nova view "address", edite myproj/myapp/urls.py (não myproj/urls.py) e adicione:
url(r'^addr/(?P<lid>\w+)$', address),
Substitua também a linha
from myapp.views import index
por
from myapp.views import index , address
A seguir, mostramos o arquivo completo (mudanças em negrito):
from django.conf.urls.defaults import *
from myapp.views import index
, address
urlpatterns = patterns('',
url(r'^addr/(?P<lid>\w+)$', address),
url(r'^$', index),
) 
Esta nova regra vai identificar correspondências com as URL com o seguinte formato:
//.../myapp/addr/1234
Neste exemplo, o parâmetro "lid" será estabelecido em 1234 e enviado para a view "address".
Para testar a nova lista, chame explicitamente em um navegador Web.
//127.0.0.1:8000/myapp/addr/1000

Agora, é possível modificar a view "index" para usar a view "adress" de modo a mudar dinamicamente a página mostrada.
Edite myapp/templates/index.html e faça as seguintes mudanças. Abaixo, mostramos o arquivo completo para facilitar sua cópia.
Adicione uma nova seção HTML abaixo da tabela:
<p>
<div id="outputNode"></div>
</p> Inicialmente, não contém nenhum texto que possa ser usado como saída. Quando a página for carregada, nada será visível abaixo da tabela. Quando o exemplo estiver completo, o código de Javascript será executado clicando um link, e o conteúdo de texto da seção outputNode será atualizado. Então, o navegador Web mostrará o novo valor sem precisar de uma atualização completa da página.
Agora, adicione um link para ser clicado. Substitua o texto do template.
<td>{{loc.location_id}}</td>
por
<td><a href="//this_link_goes_nowhere/"
onClick="makeRequest({{loc.location_id}}); return false;">
{{loc.location_id}}<a></td>
Assim, todos os identificadores de localizações serão transformados em links. O link é estabelecido com uma URL não válida; mas esse não é um problema, pois esta nunca será chamada. Em vez disso, o evento onClick chamará uma nova função de Javascript que vamos criar. O valor de location_id é enviado para a função (substituído pela expansão do template do Django). O comando "return false;" evita a ação predeterminada de HREF que chamaria uma URL não válida (neste exemplo).
Por último, adicione a função de Javascript que cria uma solicitação HTTP assíncrona na tag <head>:
<script type="text/javascript">
function makeRequest(id)
{
httpRequest = new XMLHttpRequest();
httpRequest.open('POST', '//127.0.0.1:8000/myapp/addr/' + id);
httpRequest.onreadystatechange = function()
{
if (httpRequest.readyState == 4) {
// The request is complete
var JSONtext = httpRequest.responseText;
var myArray = eval('(' + JSONtext + ')');
// beware security issues
var txt = "Selected address is:<br>";
for (var i = 0; i < myArray.length; ++i) {
txt = txt + myArray[i]["STREET_ADDRESS"] + '<br>'
+ myArray[i]["CITY"] + " " + myArray[i]["POSTAL_CODE"] + '<br>'
+ myArray[i]["COUNTRY"];
}
document.getElementById("outputNode").innerHTML = txt;
}
}
httpRequest.send(null);
}
</script>
Esta função é chamada quando um identificador de localização é clicado. Esta estabelece que a URL será invocada como //127.0.0.1:8000/myapp/addr/ com o identificador de localização anexado.
A linha no final do código de Javascript
httpRequest.send(null);
inicia a solicitação HTTP, mas antes disso, uma função anônima que vai processar os dados retornados é alocada à ação onreadystatechange.
A função de mudança de estado é chamada de forma assíncrona quando o estado da solicitação mudou. Esta verifica se o solicitação está completa. Se for assim, o método eval transformará a cadeia JSON obtida em um objeto de Javascript. A matriz myArray resultante pode ser diretamente usada em Javascript. Neste exemplo, o laço só será executado uma vez porque LOCATION_ID é uma chave primária. O corpo do laço concatena os campos de dados do endereço em uma cadeia única.
É conveniente levar em conta possíveis problemas de segurança associados ao uso que descrevemos de eval(). Para um sistema de produção, é mais seguro usar algum dos diversos analisadores de JSON fornecidos por terceiros.
A linha
document.getElementById("outputNode").innerHTML = txt;
substitui o conteúdo da página da seção div outputNode pelo endereço.

A seguir, mostramos o arquivo myproj/myapp/templates/index.html completo (mudanças em negrito):
<html>
<head>
<title>Office Locations</title>
<script type="text/javascript">
function makeRequest(id)
{
httpRequest = new XMLHttpRequest();
httpRequest.open('POST', '//127.0.0.1:8000/myapp/addr/' + id);
httpRequest.onreadystatechange = function()
{
if (httpRequest.readyState == 4) {
// The request is complete
var JSONtext = httpRequest.responseText;
var myArray = eval('(' + JSONtext + ')');
// beware security issues
var txt = "Selected address is:<br>";
for (var i = 0; i < myArray.length; ++i) {
txt = txt + myArray[i]["STREET_ADDRESS"] + '<br>'
+ myArray[i]["CITY"] + " " + myArray[i]["POSTAL_CODE"] + '<br>'
+ myArray[i]["COUNTRY"];
}
document.getElementById("outputNode").innerHTML = txt;
}
}
httpRequest.send(null);
}
</script>
</head>
<body bgcolor="#ffffff">
<h1>Office Locations</h1>
<table border="1">
<tr>
<th>Location ID</th>
<th>Street Address</th>
<th>City</th>
</tr>
{% for loc in locations %}
<tr>
<td><a href="//this_link_goes_nowhere/"
onClick="makeRequest({{loc.location_id}}); return false;">
{{loc.location_id}}<a></td>
<td>{{loc.street_address}}</td>
<td>{{loc.city}}</td>
</tr>
{% endfor %}
</table>
<p>
<div id="outputNode"></div>
</p>
</body>
</html>
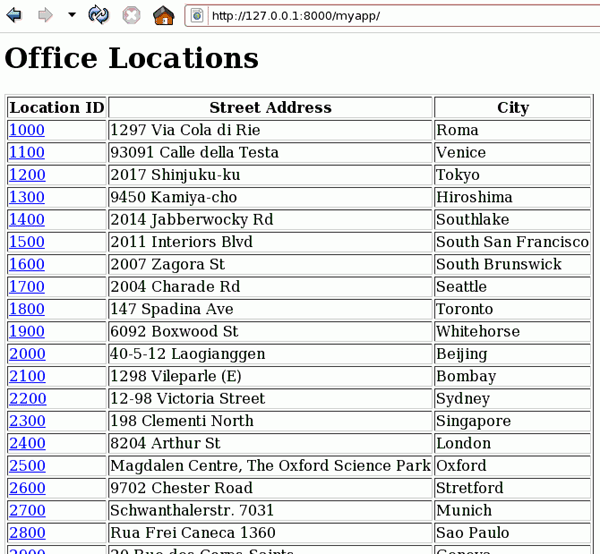
Agora, execute a aplicação carregando a URL do índice em um navegador Web:
//127.0.0.1:8000/myapp/
Agora, todos os identificadores de localização são links.
Passe o mouse sobre qualquer um deles. A barra de estado na parte inferior do navegador mostrará a URL //this_link_goes_nowhere/.
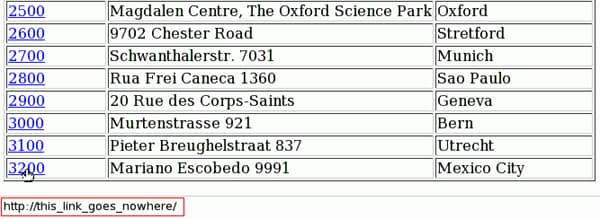
Clique no último identificador de localização, "3200". A URL não válida não será chamada. Em vez disso, é chamada a função de Javascript e, abaixo da tabela, é mostrado o endereço completo do escritório do México (talvez seja necessário você se deslocar para baixo). Com o lento servidor Web de desenvolvimento incluído no Django, a carga dos dados pode levar um ou dois segundos:

Quando usada criteriosamente, a técnica AJAC pode melhorar o desempenho e a capacidade de utilização das aplicações Web. Esta pode ser usada para mostrar ou enviar dados, e, assim, permite criar aplicações complexas.
Sumário Neste tutorial, você aprendeu a:
- criar uma conexão;
- usar a característica de pool de conexões existentes de bancos de dados;
- criar uma pesquisa simples;
- obter dados;
- melhorar o desempenho das pesquisas;
- usar variáveis de ligação de ligação;
- criar transações;
- usar funções e procedimentos armazenados de PL/SQL;
- usar notificações de pesquisa contínua;
- usar o ambiente de desenvolvimento Django;
- usar AJAX com Python.
Apêndice: Conceitos básicos de Python Python é uma linguagem de programação dinâmica. É comumente usada para executar sequências de linha de comando, mas também é utilizada em aplicações Web. As cadeias podem ser delimitadas entre aspas simples ou duplas:
'A string constant' "another constant"
As cadeias de mais de uma linha são delimitadas por pares de aspas tríplices.
""" This is your string """
Não é necessário declarar tipos de variáveis.
count = 1 ename = 'Arnie'
As matrizes associativas são chamadas de "dictionaries" [dicionários].
a2 = {'PI':3.1415, 'E':2.7182}
As matrizes ordenadas são chamadas de "lists" ´[listas]:
a3 = [101, 4, 67]
As tuplas são como as listas, mas não podem ser modificadas após ter sido criadas. São criadas usando parênteses.
a4 = (3, 7, 10)
Cadeias e variáveis podem ser mostradas com o comando print:
print 'Hello, World!' print 'Hi', x
Também é possível gerar uma saída com formato:
print "There are %d %s" % (v1, v2)
Todos os elementos do Python são objetos. Por exemplo, o método append() pode ser usado para adicionar um valor na lista a3 acima.
a3.append(23)
Agora a3 inclui [101, 4, 67, 23]
O fluxo do código pode ser controlado com testes e laços. Os comandos if/elif/else são expressos da seguinte maneira:
if sal > 900000: print 'Salary is way too big' elif sal > 500000: print 'Salary is huge' else: print 'Salary might be OK'
Vemos também no exemplo que as cláusulas são delimitadas com ":" e que cada sub-bloco de código é recuado. A seguir, mostramos um laço tradicional:
for i in range(0, 10): print i
A sequência acima mostra os números do 0 ao 9. O valor de i é incrementado a cada iteração. O comando "for" pode ser usado ainda para realizar iterações através de listas e tuplas.
a5 = ['Aa', 'Bb', 'Cc'] for v in a5: print v
A sequência acima define v para cada elemento da lista a5, um de cada vez. Funções podem ser definidas:
def myfunc(p1, p2): "Function documentation: add two numbers" print p1, p2 return p1 + p2 As funções podem retornar ou não valores. Esta função poderia ser chamada com o seguinte comando:
v3 = myfunc(1, 3)
As chamadas a funções devem ser incluídas após a definição da função. As funções também são objetos e têm atributos. O atributo __doc__ integrado pode ser usado para encontrar a descrição de uma função:
print myfunc.__doc__
O comando import permite incluir sub-arquivos nas sequências do Python.
import os import sys
Há grande quantidade de módulos predefinidos, como os módulos os e sys. Os comentários podem ser de apenas uma linha, como
# a short comment
ou de várias linhas; para isso, é necessário usar pares de aspas tríplices:
""" a longer comment """